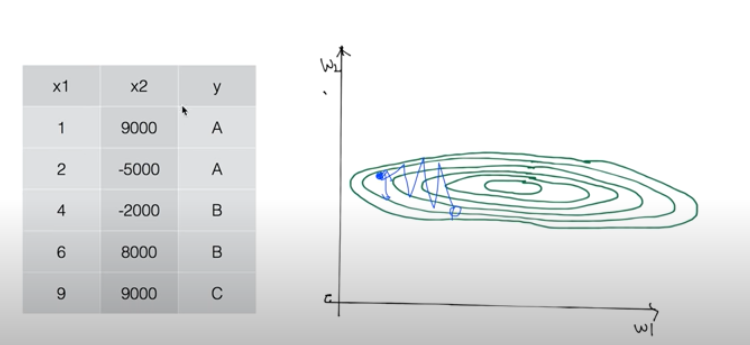
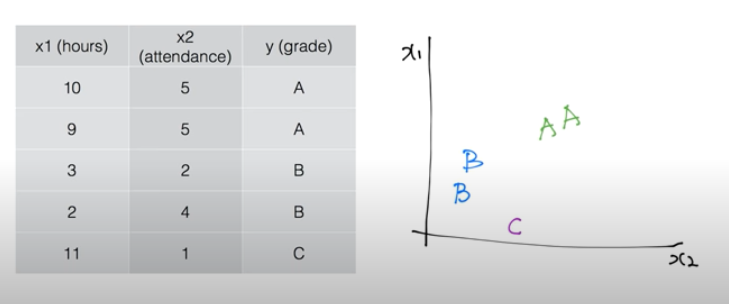
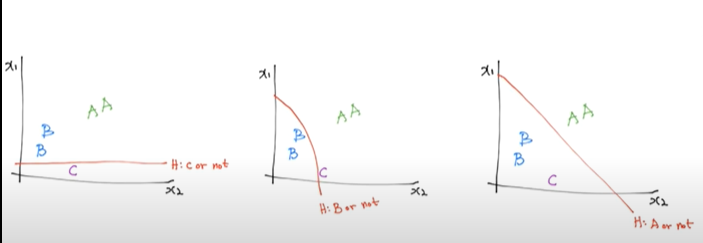
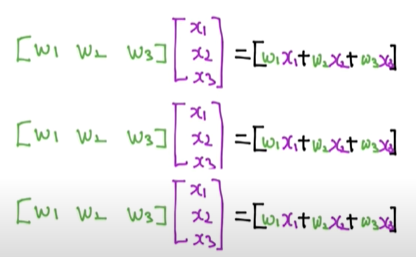
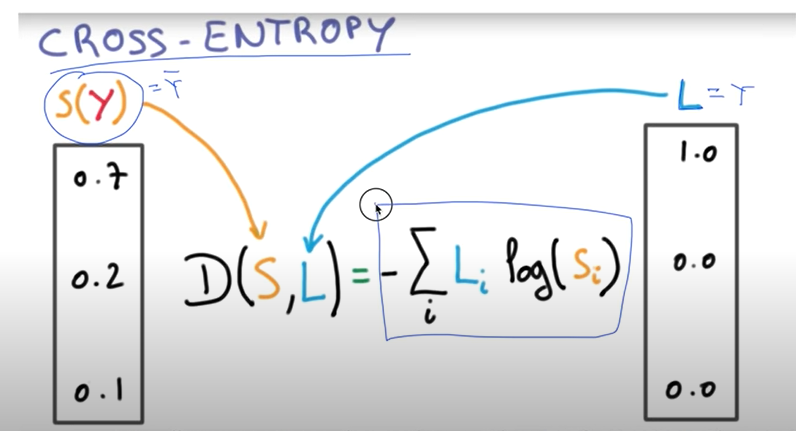
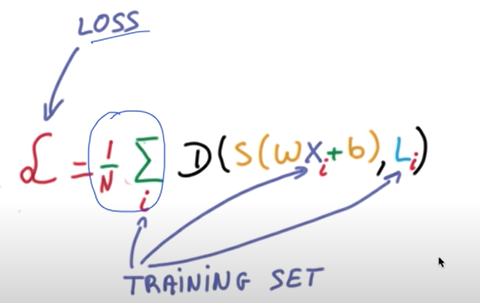
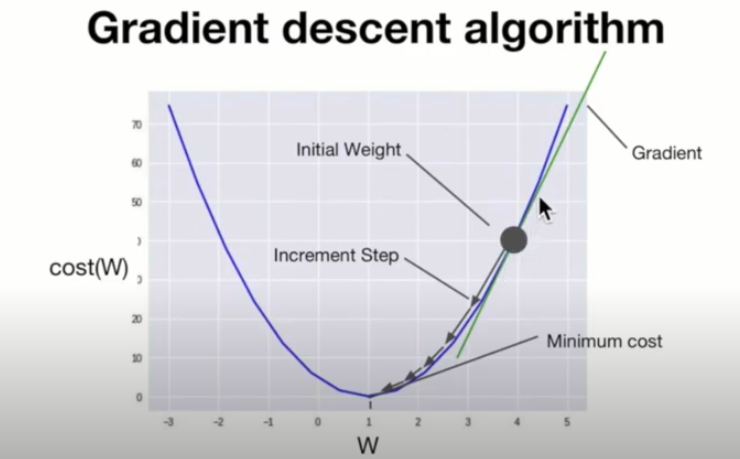
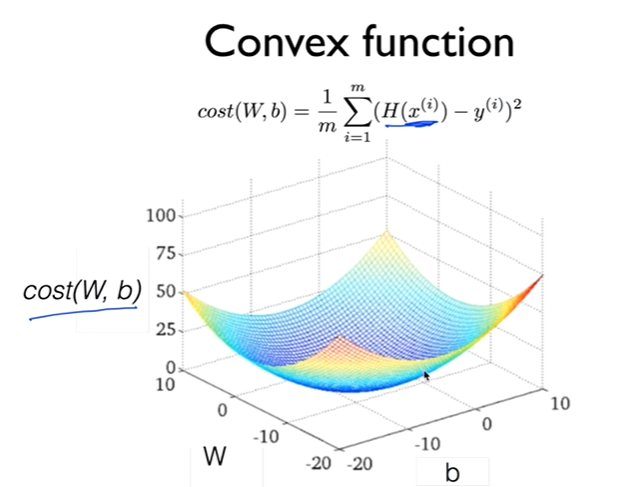
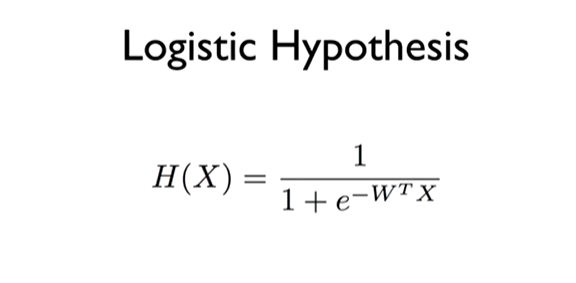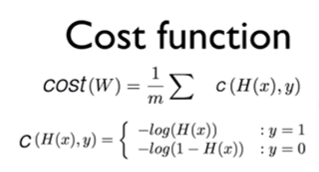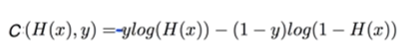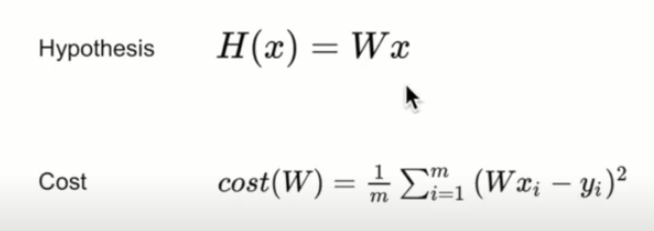우리가 만든 머신러닝 모델이 얼마나 잘 작동하는지 확인하는 방법에 대해 알아보겠다.
일정한 학습 데이터 셋(Training data set)를 이용하여 모델을 만들고 같은 데이터 셋으로 모델을 테스트하면 당연하게 올바른 결과가 나올 것이다. 그러나 같은 데이터 셋을 사용하여 테스트하는 것은 실질적으로 의미가 없다. 다른 데이터가 들어올 때 올바르게 반응해야 그것이 제대로 된 모델이라고 할 수 있다.
그렇게 학습 때와는 다른 데이터로 모델을 테스트하기 위해 우리는 데이터 셋에서 Training을 위한 데이터와 Test를 위한 데이터를 나눌 필요가 있다.
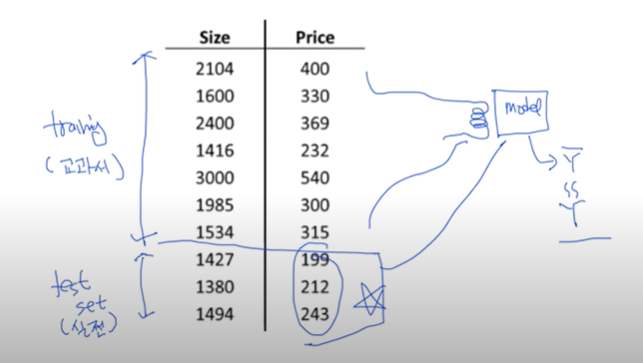
위의 사진과 같이 우리가 가지고 있는 데이터 셋에서 학습을 위한 데이터와 테스트를 위한 데이터를 나누고 실제 모델을 만들 때는 학습 데이터 셋만을 사용하여 모델을 생성하고 생성된 모델을 가지고 테스트 데이터 셋을 사용하여 모델이 잘 만들어졌는지 테스트해본다. ( 보통 Training data와 Test data는 7:3의 비율 정도로 나눈다고 함 )

위와 같이 Traing data와 Testing data를 나눌 수 있는데 특별히 우리가 필요한 알파나 람다와 같은 상수를 정해주기 위해 training data를 Training data와 Validation data로 나누기도 한다. ( Validation data를 이용하는 것은 시험을 치기 위해 모의고사를 보는 것과 비슷한 의미 )
Online learning
데이터 셋이 많을 때 메모리와 같은 부분이 부족할 수 있기 때문에 이 데이터를 나누어서 학습을 시켜주는 것을 Online learning이라고 한다. ( 학습 데이터가 추가될 경우에 사용하는 방식이기도 하다. )
Mnist Dataset
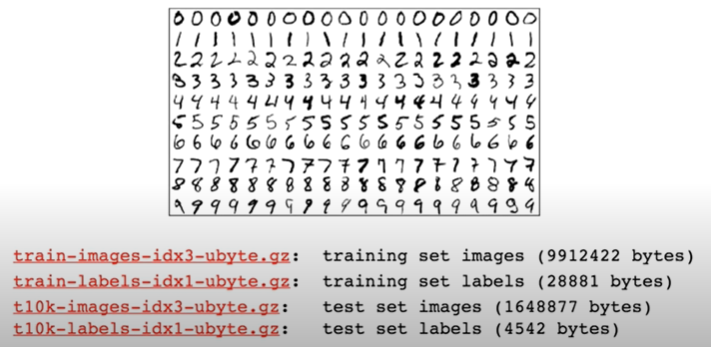
위와 같이 숫자를 구별하는 모델을 위한 유명한 데이터 셋인 Mnist Dataset도 마찬가지로 Training을 위한 데이터( images, labels )와 Testing을 위한 데이터( images, labels )가 나누어져 있는 것을 볼 수 있다.
결과적으로 Training dataset을 이용하여 학습한 모델을 만들고 Testing dataset으로 Accuracy(정확도)를 알아내어 높은 정확도의 모델을 만드는 것이 최종 목적이다.
그렇다면 실습을 통해 소스코드를 구현해보자.
import tensorflow as tf
x_data = [[1, 2, 1],
[1, 3, 2],
[1, 3, 4],
[1, 5, 5],
[1, 7, 5],
[1, 2, 5],
[1, 6, 6],
[1, 7, 7]]
y_data = [[0, 0, 1],
[0, 0, 1],
[0, 0, 1],
[0, 1, 0],
[0, 1, 0],
[0, 1, 0],
[1, 0, 0],
[1, 0, 0]]
# Evaluation our model using this test dataset
x_test = [[2, 1, 1],
[3, 1, 2],
[3, 3, 4]]
y_test = [[0, 0, 1],
[0, 0, 1],
[0, 0, 1]]
X = tf.placeholder("float", [None, 3])
Y = tf.placeholder("float", [None, 3])
W = tf.Variable(tf.random_normal([3, 3]))
b = tf.Variable(tf.random_normal([3]))
# 가설 및 entropy 함수를 통한 cost function 구현
hypothesis = tf.nn.softmax(tf.matmul(X, W)+b)
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
# ONE-HOT encoding을 통해 변환한 예측값, 실제값을 비교하여 정확도 측정
prediction = tf.argmax(hypothesis, 1)
is_correct = tf.equal(prediction, tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
# Launch graph
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 학습 데이터를 통한 학습 과정
for step in range(201):
cost_val, W_val, _ = sess.run([cost, W, optimizer],
feed_dict={X: x_data, Y: y_data})
print(step, cost_val, "\n", W_val)
# predict
print("Prediction: ", sess.run(prediction, feed_dict={X: x_test}))
# Calculate the accuracy
print("Accuracy: ", sess.run(accuracy, feed_dict={X: x_test, Y: y_test}))
우선 학습을 위한 x_data, y_data 그리고 테스트를 위한 x_test, y_test로 데이터를 나눈다.
이전과 같은 방식으로 학습 데이터를 통해 모델을 만들고 테스트 데이터를 통해 모델을 평가한다.
결과

결과적으로 학습 데이터를 통해 만든 모델이 우리가 설정한 테스트 데이터에서도 100%의 확률로 예측에 성공하였다는 것을 볼 수 있다. 이로써 training dataset과 testing dataset을 나누어 우리의 모델을 평가하는 부분까지 끝났다.
이제는 이런 평가를 통해 이전에 공부했던 Learning rate 적정값 설정의 필요성과 Normalization의 필요성을 소스코드를 통해 이해해보자.
앞선 코드에서는 learning_rate를 0.1로 주었는데 이번에는 1.5와 1e-20으로 각각 주어주고 결과값을 확인해보자.
결과 (learning_rate=1.5)

결과 (learning_rate=1e-20)

learning_rate를 크게 설정하니 cost 값이 nan이 되고 결과적으로 정확도가 0이 되는 것을 확인할 수 있다.
또한, learning_rate를 작게 설정하니 cost 값이 일정 횟수 이상이 될때 같은 결과로 나오며 이 또한 정확도가 0이 되는 것을 확인할 수 있다.
learning rate을 잘 설정했음에도 불구하고 nan이 나오는 경우가 있는데 많은 이유 중 하나가 input 데이터가 Normalized 되지 않았기 때문이다. Normalization의 한 예로 아래와 같이 MinMaxScaler이라는 함수를 사용하여 0~1 사이의 값으로 변경시켜주고 그 데이터를 input 데이터로 사용한다.

Non-normalized input을 이용한 소스코드
import tensorflow as tf
import numpy as np
xy = np.array([[828.659973, 833.450012, 908100, 828.349976, 831.659973],
[823.02002, 828.070007, 1828100, 821.655029, 828.070007],
[819.929993, 824.400024, 1438100, 818.97998, 824.159973],
[816, 820.958984, 1008100, 815.48999, 819.23999],
[819.359985, 823, 1188100, 818.469971, 818.97998],
[819, 823, 1198100, 816, 820.450012],
[811.700012, 815.25, 1098100, 809.780029, 813.669983],
[809.51001, 816.659973, 1398100, 804.539978, 809.559998]])
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
X = tf.placeholder("float", [None, 4])
Y = tf.placeholder("float", [None, 1])
W = tf.Variable(tf.random_normal([4, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
hypothesis = tf.matmul(X, W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for step in range(2001):
cost_val, hy_val, _ = sess.run([cost, hypothesis, train], feed_dict={X: x_data, Y: y_data})
print(step, "Cost: ", cost_val, "\nPrediction:\n", hy_val)
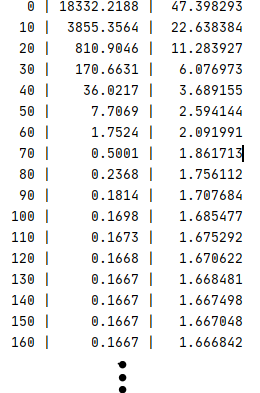
결과

Normalized input을 이용한 소스코드
import tensorflow as tf
import numpy as np
def min_max_scaler(data):
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
# noise term prevents the zero division
return numerator / (denominator + 1e-7)
xy = np.array([[828.659973, 833.450012, 908100, 828.349976, 831.659973],
[823.02002, 828.070007, 1828100, 821.655029, 828.070007],
[819.929993, 824.400024, 1438100, 818.97998, 824.159973],
[816, 820.958984, 1008100, 815.48999, 819.23999],
[819.359985, 823, 1188100, 818.469971, 818.97998],
[819, 823, 1198100, 816, 820.450012],
[811.700012, 815.25, 1098100, 809.780029, 813.669983],
[809.51001, 816.659973, 1398100, 804.539978, 809.559998]])
xy = min_max_scaler(xy)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
X = tf.placeholder("float", [None, 4])
Y = tf.placeholder("float", [None, 1])
W = tf.Variable(tf.random_normal([4, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
hypothesis = tf.matmul(X, W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for step in range(2001):
cost_val, hy_val, _ = sess.run([cost, hypothesis, train], feed_dict={X: x_data, Y: y_data})
print(step, "Cost: ", cost_val, "\nPrediction:\n", hy_val)
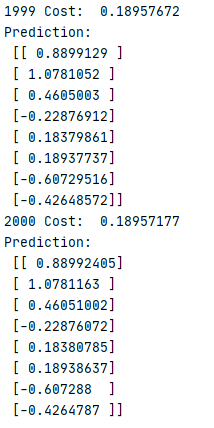
결과
'Machine Learning & Deep Learning' 카테고리의 다른 글
| 12. Neural Nets(NN) for XOR (0) | 2020.04.28 |
|---|---|
| 11. Deep Neural Nets (0) | 2020.04.28 |
| 9. Learning rate, Data preprocessing, overfitting (0) | 2020.04.23 |
| 8. Softmax classification (0) | 2020.04.22 |
| 7. Logistic Regression (0) | 2020.04.20 |