이제까지는 하나의 Input일 때의 경우에 Hypothesis를 정의하는 법과 Cost function의 Minimize를 구하는 법을 공부하였지만 실제의 Input 데이터는 하나가 아닌 여러 개일 경우가 많다.
그렇다면 이제 하나의 Input이 아닌 여러 개의 Input일 경우 가설과 cost function을 아래와 같은 식으로 나타낼 수 있다.

그런데 Input이 많아지면 각각의 항을 일일이 구현하는 것이 불편하고 이는 Matrix를 사용함으로 아래와 같이 간편하게 구현할 수 있다.
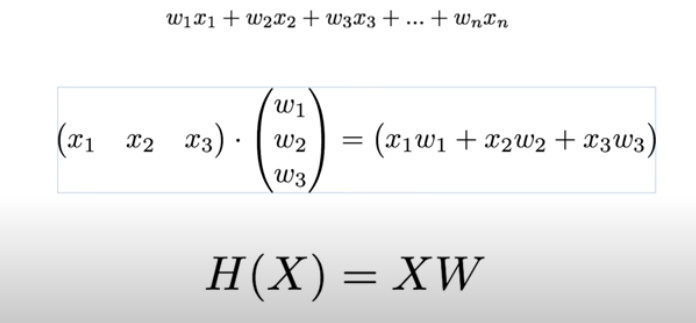
또한, Matrix로 구현하는 hypothesis는 학습 데이터의 개수인 instance가 늘어나도 아래와 같이 간편하게 구현할 수 있는 장점을 가지고 있다.

여기서 확인할 수 있는 하나의 특징은 instance가 늘어나도 W의 Matrix는 원래의 모양을 유지한다는 것이다.
이렇듯이 전체의 데이터를 하나의 Matrix로 관리할 수 있기 때문에 편리하다.
또한, 여러 개의 input이 존재할 수 있다면 여러 개의 output 역시 존재할 수 있다.
n개의 input과 2개의 output이 존재하는 가설을 세우고 싶다면 아래와 같은 Matrix 형태가 될 것이다.
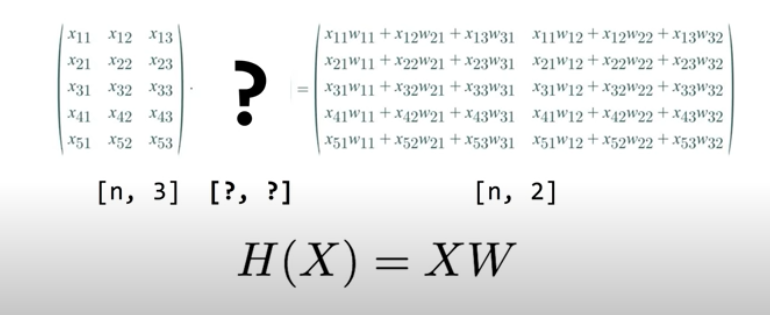
TensorFlow에서는 n을 None으로 표시하고 Numpy는 -1이라 표시한다.
그렇다면 [?, ?]에 들어갈 값은 앞 행렬의 열을 행으로 뒷 행렬의 열을 열으로 가져서 [3, 2]가 될 것이다.
이런 방식으로 input과 output을 통해 W의 Matrix 형태를 정해줄 수 있다.
그렇다면, 공부했던 것들을 TensorFlow를 이용하여 실습하며 이해해보자.
우선, Matrix를 사용하지 않고 구현을 해보겠다.
import tensorflow as tf
# 데이터 셋, label(y)
x1 = [ 73., 93., 89., 96., 73.]
x2 = [ 80., 88., 91., 98., 66.]
x3 = [ 75., 93., 90., 100., 70.]
Y = [152., 185., 180., 196., 142.]
# weight(W), bias(b)
w1 = tf.Variable(tf.random.normal([1]))
w2 = tf.Variable(tf.random.normal([1]))
w3 = tf.Variable(tf.random.normal([1]))
b = tf.Variable(tf.random.normal([1]))
learning_rate = 0.000001
for i in range(1000+1):
# tf.GradientTape()를 통한 Gradient descent 구현
with tf.GradientTape() as tape:
hypothesis = w1 * x1 + w2 * x2 + w3 * x3 + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# tape을 이용하여 반환된 w1, w2, w3, b의 기울기를 변수에 저장
w1_grad, w2_grad, w3_grad, b_grad = tape.gradient(cost, [w1, w2, w3, b])
# w1, w2, w3, b를 업데이트
w1.assign_sub(learning_rate * w1_grad)
w2.assign_sub(learning_rate * w2_grad)
w3.assign_sub(learning_rate * w3_grad)
b.assign_sub(learning_rate * b_grad)
if i % 50 == 0:
print("{:5} | {:12.4f}".format(i, cost))
결과

위의 결과를 보면 cost 값이 작은 값으로 수렴되고 있음을 확인할 수 있다.
그렇다면 이제, Matrix를 이용하여 학습을 구현해보자.
import tensorflow as tf
import numpy as np
# 데이터 행렬
data = np.array([
[73., 80., 75., 152.],
[93., 88., 93., 185.],
[89., 91., 90., 180.],
[96., 98., 100., 196.],
[73., 66., 70., 142.]
], dtype=np.float32)
# slice data
# X 데이터는 행렬의 전체행, 마지막 열 제외 값
# Y 데이터는 행렬의 전체행, 마지막 열
X = data[:, :-1]
Y = data[:, [-1]]
# W의 값은 앞선 이론에서 공부했듯이 [X의 열 갯수, Y의 열 갯수]로 나타낼 수 있다.
W = tf.Variable(tf.random.normal([3, 1]))
b = tf.Variable(tf.random.normal([1]))
learning_rate = 0.000001
# 우리의 가설을 행렬곱을 이용하여 반환
def predict(X):
return tf.matmul(X, W) + b
# 2000번의 순회 (epoch는 순회의 횟수를 의미)
n_epochs = 2000
for i in range(n_epochs + 1):
with tf.GradientTape() as tape:
cost = tf.reduce_mean(tf.square(predict(X) - Y))
W_grad, b_grad = tape.gradient(cost, [W, b])
W.assign_sub(learning_rate * W_grad)
b.assign_sub(learning_rate * b_grad)
if i % 100 == 0:
print("{:5} | {:10.4f}".format(i, cost.numpy()))
결과

위에서 Matrix 방식을 쓴 코드와 쓰지 않은 코드를 비교해보면 Matrix를 쓴 코드가 훨씬 간편하게 구현하였음을 직관적으로 확인할 수 있고 데이터가 더욱 많아질수록 이런 차이는 극심해질 것이다.
따라서 우리는 Matrix로 우리의 가설을 세우는 방식을 추구해야 한다.
'Machine Learning & Deep Learning' 카테고리의 다른 글
| 7. Logistic Regression (0) | 2020.04.20 |
|---|---|
| 6. Loading Data from File (0) | 2020.04.18 |
| 4. Hypothesis and Cost (0) | 2020.04.16 |
| 3. Linear Regression (0) | 2020.04.15 |
| 2. Tensorflow 사용 환경 구축 (0) | 2020.04.15 |